Publications
2026
-
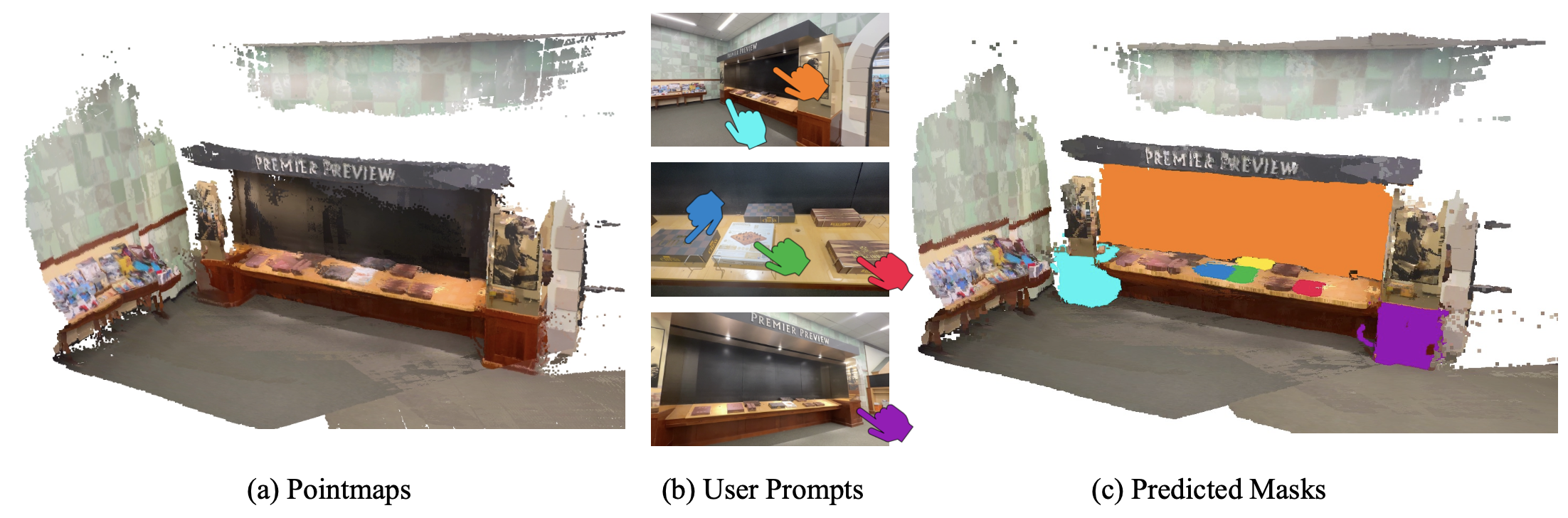 MV-SAM: Multi-view Promptable Segmentation using Pointmap GuidanceYoonwoo Jeong, Cheng Sun, Yu-Chiang Frank Wang, Minsu Cho, and Jaesung ChoeNVIDIA tech report, 2026
MV-SAM: Multi-view Promptable Segmentation using Pointmap GuidanceYoonwoo Jeong, Cheng Sun, Yu-Chiang Frank Wang, Minsu Cho, and Jaesung ChoeNVIDIA tech report, 2026Promptable segmentation has emerged as a powerful paradigm in computer vision, enabling users to guide models in parsing complex scenes with prompts such as clicks, boxes, or textual cues. Recent advances, exemplified by the Segment Anything Model (SAM), have extended this paradigm to videos and multi-view images. However, the lack of 3D awareness often leads to inconsistent results, necessitating costly per-scene optimization to enforce 3D consistency. In this work, we introduce MV-SAM, a framework for multi-view segmentation that achieves 3D consistency using pointmaps–3D points reconstructed from unposed images by recent visual geometry models. Leveraging the pixel–point one-to-one correspondence of pointmaps, MV-SAM lifts images and prompts into 3D space, eliminating the need for explicit 3D networks or annotated 3D data. Specifically, MV-SAM extends SAM by lifting image embeddings from its pretrained encoder into 3D point embeddings, which are decoded by a transformer using cross-attention with 3D prompt embeddings. This design aligns 2D interactions with 3D geometry, enabling the model to implicitly learn consistent masks across views through 3D positional embeddings. Trained on the SA-1B dataset, our method generalizes well across domains, outperforming SAM2-Video and achieving comparable performance with per-scene optimization baselines on NVOS, SPIn-NeRF, ScanNet++, uCo3D, and DL3DV benchmarks. Code will be released.


2025
-
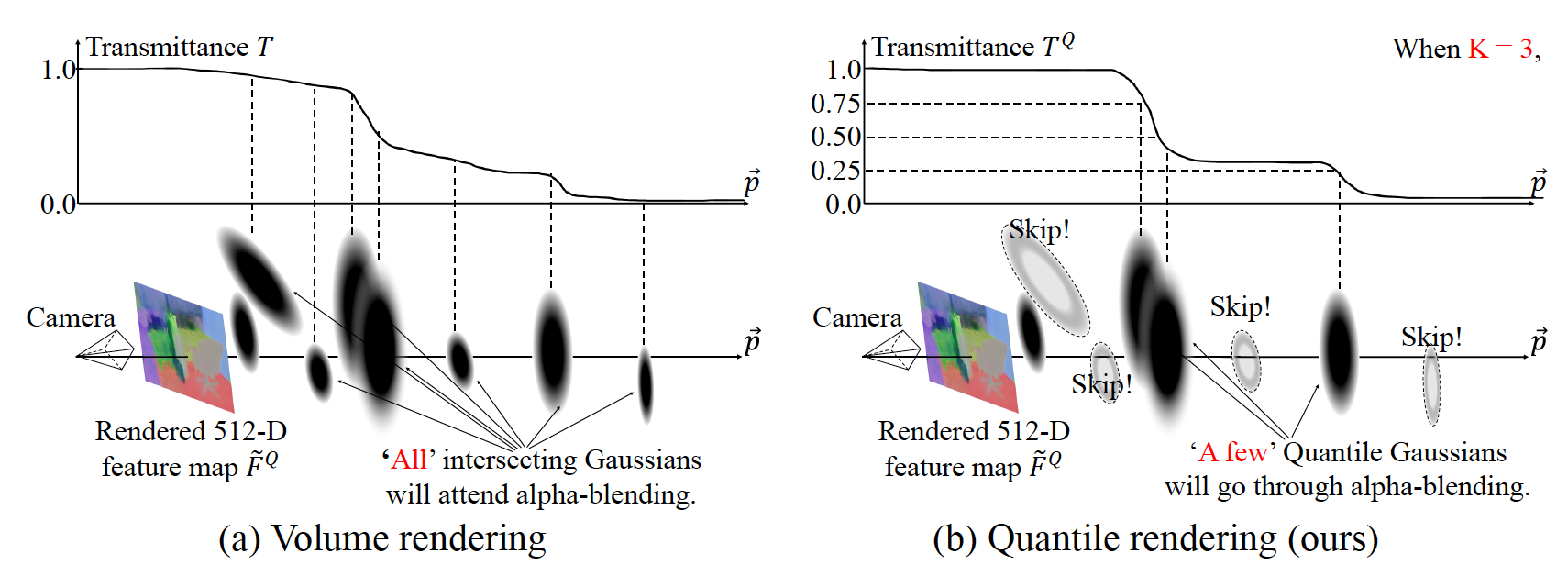 Quantile Rendering: Efficiently Embedding High-dimensional Feature on 3D Gaussian SplattingYoonwoo Jeong, Cheng Sun, Yu-Chiang Frank Wang, Minsu Cho, and Jaesung ChoeNVIDIA tech report, 2025
Quantile Rendering: Efficiently Embedding High-dimensional Feature on 3D Gaussian SplattingYoonwoo Jeong, Cheng Sun, Yu-Chiang Frank Wang, Minsu Cho, and Jaesung ChoeNVIDIA tech report, 2025We present Quantile Rendering (Q-Render), an efficient rendering algorithm for 3D Gaussians that involve high-dimensional feature vectors. Unlike conventional volume rendering, which densely samples all 3D Gaussians intersecting each ray, Q-Render sparsely samples 3D Gaussians that have dominant influence along ray. The dominance is determined by transmittance change analysis, and the only sampled Gaussians will participate in subsequent rendering steps such as alpha blending. In our framework, Q-Render is integrated with a conventional 3D neural network that operates on 3D Gaussians, named Gaussian Splatting Network (GS-Net), to predict Gaussian features. We evaluate GS-Net on open-vocabulary 3D semantic segmentation using two benchmarks: (1) ScanNet and (2) LeRF-OVS, where 3D Gaussians are enriched with CLIP-based language features. Extensive experiments show that Q-Render under GS-Net consistently outperforms existing methods, achieving superior results and highlighting its potential as an effective bridge between 2D foundation models and 3D Gaussian representations. Furthermore, our Q-render achieves 43.7× speed gains against previous methods when rendering 512-D feature maps.

2024
-
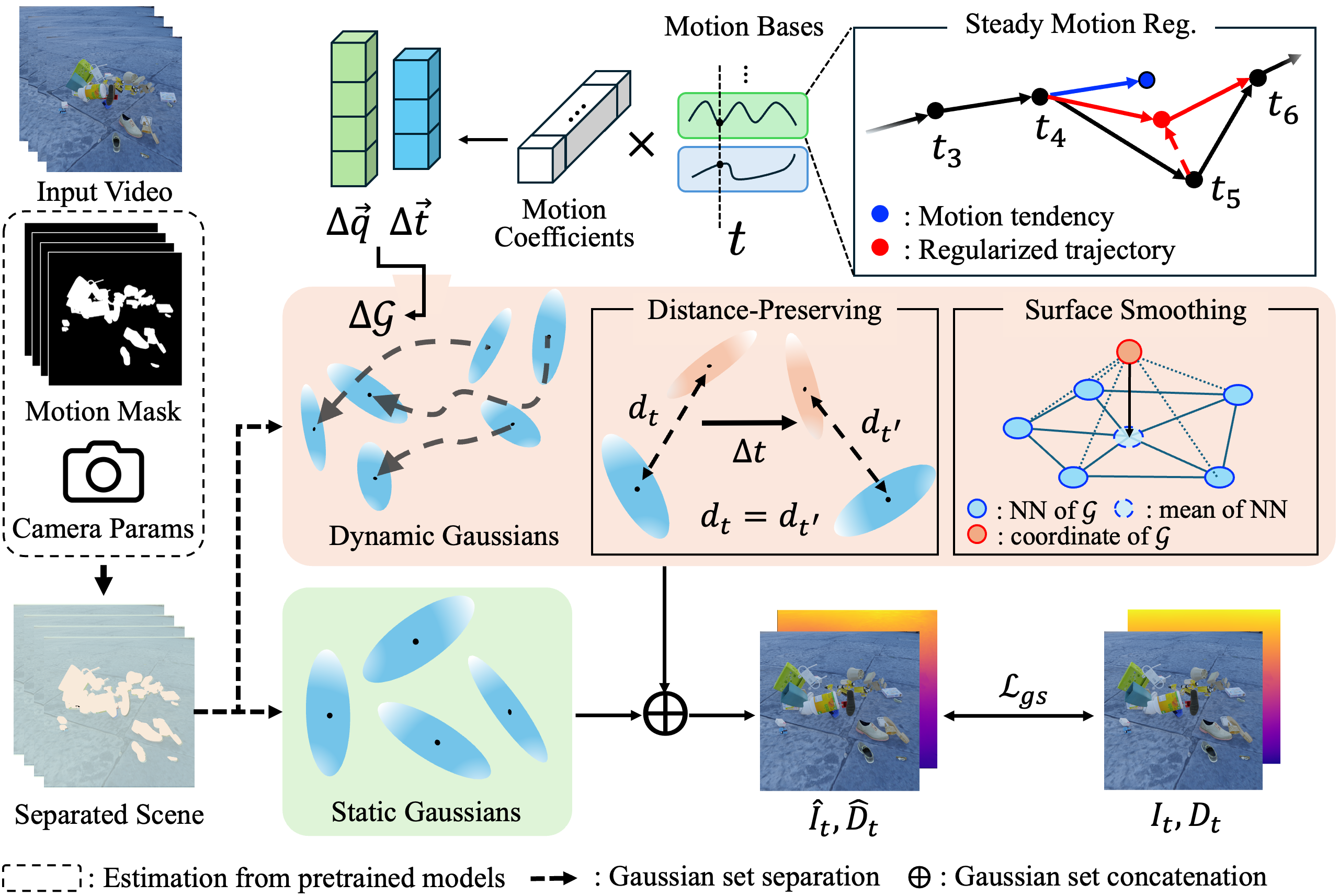 RoDyGS: Robust Dynamic Gaussian Splatting for Casual VideosYoonwoo Jeong, Junmyeong Lee, Hoseung Choi, and Minsu ChoarXiv preprint, 2024
RoDyGS: Robust Dynamic Gaussian Splatting for Casual VideosYoonwoo Jeong, Junmyeong Lee, Hoseung Choi, and Minsu ChoarXiv preprint, 2024Dynamic view synthesis (DVS) has advanced remarkably in recent years, achieving high-fidelity rendering while reducing computational costs. Despite the progress, optimizing dynamic neural fields from casual videos remains challenging, as these videos do not provide direct 3D information, such as camera trajectories or the underlying scene geometry. In this work, we present RoDyGS, an optimization pipeline for dynamic Gaussian Splatting from casual videos. It effectively learns motion and underlying geometry of scenes by separating dynamic and static primitives, and ensures that the learned motion and geometry are physically plausible by incorporating motion and geometric regularization terms. We also introduce a comprehensive benchmark, Kubric-MRig, that provides extensive camera and object motion along with simultaneous multi-view captures, features that are absent in previous benchmarks. Experimental results demonstrate that the proposed method significantly outperforms previous pose-free dynamic neural fields and achieves competitive rendering quality compared to existing pose-free static neural fields.
-
 NVS-Adapter: Plug-and-Play Novel View Synthesis from a Single ImageYoonwoo Jeong, Jinwoo Lee, Chiheon Kim, Minsu Cho, and Doyup LeeEuropean Conference on Computer Vision (ECCV), 2024
NVS-Adapter: Plug-and-Play Novel View Synthesis from a Single ImageYoonwoo Jeong, Jinwoo Lee, Chiheon Kim, Minsu Cho, and Doyup LeeEuropean Conference on Computer Vision (ECCV), 2024Robust semantic segmentation under adverse conditions is of great importance in real-world applications. To address this challenging task in practical scenarios where labeled normal condition images are not accessible in training, we propose FREST, a novel feature restoration framework for source-free domain adaptation (SFDA) of semantic segmentation to adverse conditions. FREST alternates two steps: (1) learning the condition embedding space that only separates the condition information from the features and (2) restoring features of adverse condition images on the learned condition embedding space. By alternating these two steps, FREST gradually restores features where the effect of adverse conditions is reduced. FREST achieved a state of the art on two public benchmarks (\ie, ACDC and RobotCar) for SFDA to adverse conditions. Moreover, it shows superior generalization ability on unseen datasets.


2023
-
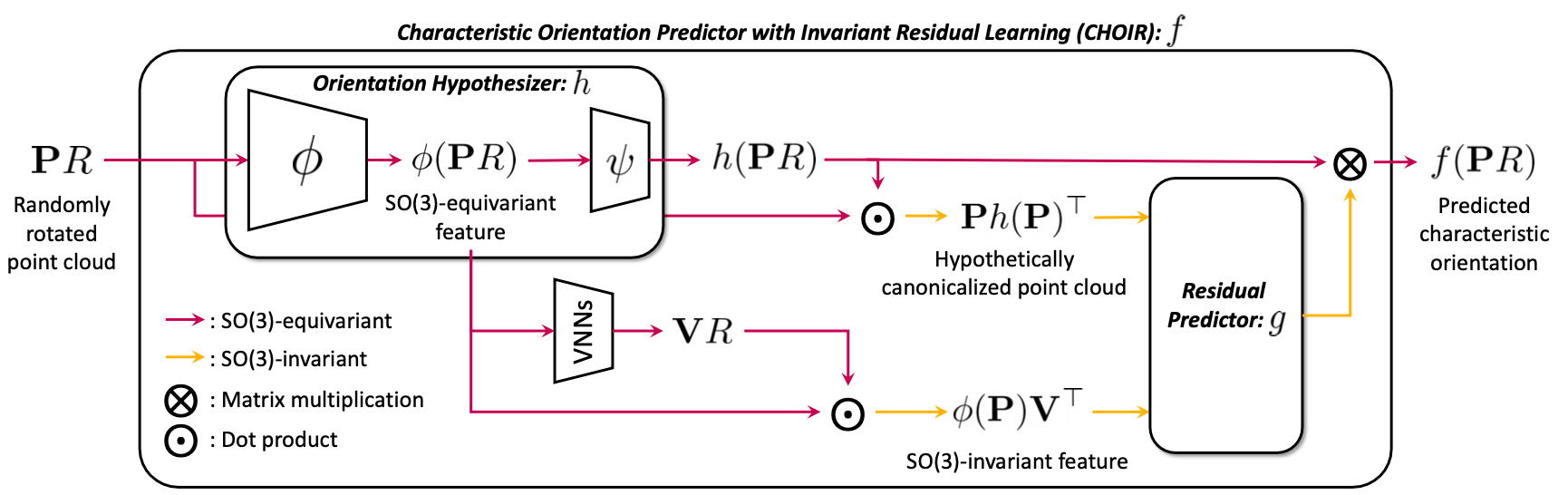 Stable and Consistent Prediction of 3D Characteristic Orientation via Invariant Residual LearningSeungwook Kim, Chunghyun Park, Yoonwoo Jeong, Jaesik Park, and Minsu ChoInternational Conference on Machine Learning (ICML), 2023
Stable and Consistent Prediction of 3D Characteristic Orientation via Invariant Residual LearningSeungwook Kim, Chunghyun Park, Yoonwoo Jeong, Jaesik Park, and Minsu ChoInternational Conference on Machine Learning (ICML), 2023Learning to predict reliable characteristic orientations of 3D point clouds is an important yet challenging problem, as different point clouds of the same class may have largely varying appearances. In this work, we introduce a novel method to decouple the shape geometry and semantics of the input point cloud to achieve both stability and consistency. The proposed method integrates shape-geometry-based SO(3)-equivariant learning and shape-semantics-based SO(3)-invariant residual learning, where a final characteristic orientation is obtained by calibrating an SO(3)-equivariant orientation hypothesis using an SO(3)-invariant residual rotation. In experiments, the proposed method not only demonstrates superior stability and consistency but also exhibits state-of-the-art performances when applied to point cloud part segmentation, given randomly rotated inputs.

2022
-
 SeLCA: Self-Supervised Learning of Canonical AxisSeungwook Kim, Yoonwoo Jeong, Chunghyun Park, Jaesik Park, and Minsu ChoConference on Neural Information Processing Systems Workshop (NeurIPS-W), 2022
SeLCA: Self-Supervised Learning of Canonical AxisSeungwook Kim, Yoonwoo Jeong, Chunghyun Park, Jaesik Park, and Minsu ChoConference on Neural Information Processing Systems Workshop (NeurIPS-W), 2022Robustness to rotation is critical for point cloud understanding tasks as point cloud features can be affected dramatically with respect to prevalent rotation changes. In this work, we introduce a novel self-supervised learning framework, dubbed SeLCA, that predicts a canonical axis of point clouds in a probabilistic manner. In essence, we propose to learn rotational-equivariance by predicting the canonical axis of point clouds, and achieve rotational-invariance by aligning the point clouds using their predicted canonical axis. When integrated into a rotation-sensitive pipeline, SeLCA achieves competitive performances on the ModelNet40 classification task under unseen rotations. Our proposed method also shows high robustness to various real-world point cloud corruptions presented by the ModelNet40-C dataset, compared to the state-of-the-art rotation-invariant method.
-
 NeRF-Factory: An awesome PyTorch NeRF collectionYoonwoo Jeong, Seungjoo Shin, and Kibaek Park2022
NeRF-Factory: An awesome PyTorch NeRF collectionYoonwoo Jeong, Seungjoo Shin, and Kibaek Park2022 -
 PeRFception: Perception using Radiance FieldsnYoonwoo Jeong*, Seungjoo Shin*, Junha Lee*, Christopher Choy, Animashree Anandkumar, Minsu Cho, and Jaesik Park (*equal contribution)Conference on Neural Information Processing Systems Dataset and Benchmark (NeurIPS-D), 2022
PeRFception: Perception using Radiance FieldsnYoonwoo Jeong*, Seungjoo Shin*, Junha Lee*, Christopher Choy, Animashree Anandkumar, Minsu Cho, and Jaesik Park (*equal contribution)Conference on Neural Information Processing Systems Dataset and Benchmark (NeurIPS-D), 2022The recent progress in implicit 3D representation, i.e., Neural Radiance Fields (NeRFs), has made accurate and photorealistic 3D reconstruction possible in a differentiable manner. This new representation can effectively convey the information of hundreds of high-resolution images in one compact format and allows photorealistic synthesis of novel views. In this work, using the variant of NeRF called Plenoxels, we create the first large-scale implicit representation datasets for perception tasks, called the PeRFception, which consists of two parts that incorporate both object-centric and scene-centric scans for classification and segmentation. It shows a significant memory compression rate (96.4%) from the original dataset, while containing both 2D and 3D information in a unified form. We construct the classification and segmentation models that directly take as input this implicit format and also propose a novel augmentation technique to avoid overfitting on backgrounds of images.
-
 Fast Point TransformerChunghyun Park, Yoonwoo Jeong, Minsu Cho, and Jaesik ParkIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Fast Point TransformerChunghyun Park, Yoonwoo Jeong, Minsu Cho, and Jaesik ParkIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022The recent success of neural networks enables a better interpretation of 3D point clouds, but processing a large-scale 3D scene remains a challenging problem. Most current approaches divide a large-scale scene into small regions and combine the local predictions together. However, this scheme inevitably involves additional stages for pre- and post-processing and may also degrade the final output due to predictions in a local perspective. This paper introduces Fast Point Transformer that consists of a new lightweight self-attention layer. Our approach encodes continuous 3D coordinates, and the voxel hashing-based architecture boosts computational efficiency. The proposed method is demonstrated with 3D semantic segmentation and 3D detection. The accuracy of our approach is competitive to the best voxel-based method, and our network achieves 129 times faster inference time than the state-of-the-art, Point Transformer, with a reasonable accuracy trade-off in 3D semantic segmentation on S3DIS dataset.
-
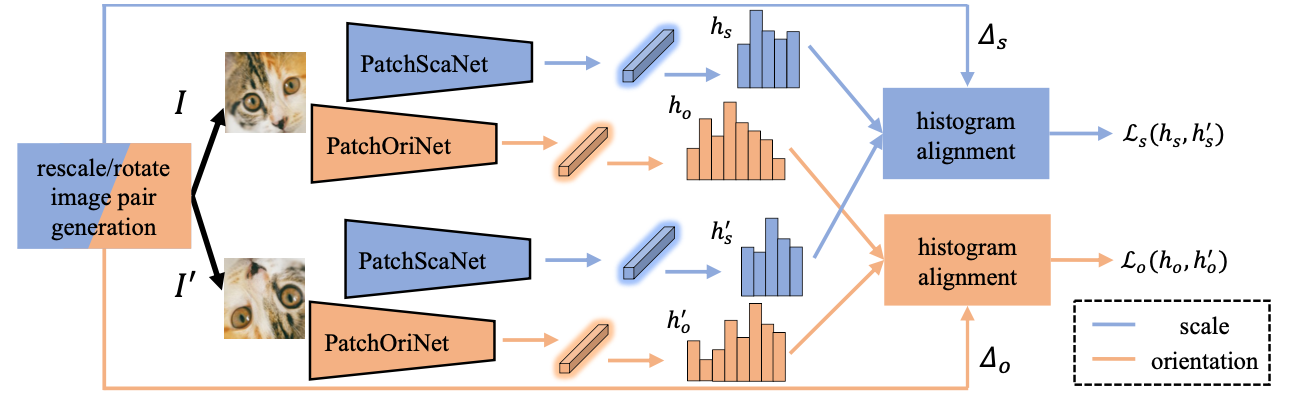 Self-supervised Learning of Image Scale and OrientationJongmin Lee, Yoonwoo Jeong, and Minsu ChoBritish Machine Vision Conference (BMVC), 2022
Self-supervised Learning of Image Scale and OrientationJongmin Lee, Yoonwoo Jeong, and Minsu ChoBritish Machine Vision Conference (BMVC), 2022We study the problem of learning to assign a characteristic pose, i.e., scale and orien- tation, for an image region of interest. Despite its apparent simplicity, the problem is non- trivial; it is hard to obtain a large-scale set of image regions with explicit pose annotations that a model directly learns from. To tackle the issue, we propose a self-supervised learn- ing framework with a histogram alignment technique. It generates pairs of image patches by random rescaling/rotating and then train an estimator to predict their scale/orientation values so that their relative difference is consistent with the rescaling/rotating used. The estimator learns to predict a non-parametric histogram distribution of scale/orientation without any supervision. Experiments show that it significantly outperforms previous methods in scale/orientation estimation and also improves image matching and 6 DoF camera pose estimation by incorporating our patch poses into a matching process.





2021
-
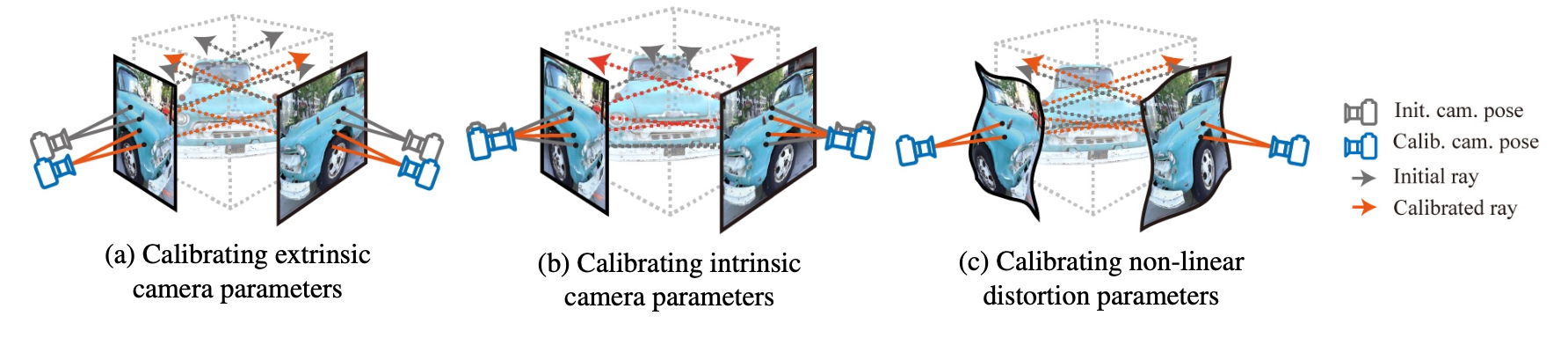 Self-calibrating Neural Radiance FieldsYoonwoo Jeong, Seokjun Ahn, Christopher Choy, Animashree Anandkumar, Minsu Cho, and Jaesik ParkIEEE/CVF Conference on International Conference on Computer Vision (ICCV), 2021
Self-calibrating Neural Radiance FieldsYoonwoo Jeong, Seokjun Ahn, Christopher Choy, Animashree Anandkumar, Minsu Cho, and Jaesik ParkIEEE/CVF Conference on International Conference on Computer Vision (ICCV), 2021In this work, we propose a camera self-calibration algorithm for generic cameras with arbitrary non-linear distortions. We jointly learn the geometry of the scene and the accurate camera parameters without any calibration objects. Our camera model consists of a pinhole model, a fourth order radial distortion, and a generic noise model that can learn arbitrary non-linear camera distortions. While traditional self-calibration algorithms mostly rely on geometric constraints, we additionally incorporate photometric consistency. This requires learning the geometry of the scene, and we use Neural Radiance Fields (NeRF). We also propose a new geometric loss function, viz., projected ray distance loss, to incorporate geometric consistency for complex non-linear camera models. We validate our approach on standard real image datasets and demonstrate that our model can learn the camera intrinsics and extrinsics (pose) from scratch without COLMAP initialization. Also, we show that learning accurate camera models in a differentiable manner allows us to improve PSNR over baselines. Our module is an easy-to-use plugin that can be applied to NeRF variants to improve performance.
-
 Learning to Distill Convolutional Features into Compact Local DescriptorsJongmin Lee, Yoonwoo Jeong, Seungwook Kim, Juhong Min, and Minsu ChoIEEE/CVF Winter Conference on Applications of Computer Vision(IJCV), 2021
Learning to Distill Convolutional Features into Compact Local DescriptorsJongmin Lee, Yoonwoo Jeong, Seungwook Kim, Juhong Min, and Minsu ChoIEEE/CVF Winter Conference on Applications of Computer Vision(IJCV), 2021Extracting local descriptors or features is an essential step in solving image matching problems. Recent methods in the literature mainly focus on extracting effective descriptors, without much attention to the size of the descriptors. In this work, we study how to learn a compact yet effective local descriptor. The proposed method distills multiple intermediate features of a pretrained convolutional neural network to encode different levels of visual information from local textures to non-local semantics, resulting in local descriptors with a designated dimension. Experiments on standard benchmarks for semantic correspondence show that it achieves significantly improved performance over existing models, with up to a 100 times smaller size of descriptors. Furthermore, while trained on a small-sized dataset for semantic correspondence, the proposed method also generalizes well to other image matching tasks, performing comparable result to the state of the art on wide-baseline matching and visual localization benchmarks.

